

R&D
With the fast growth of the Internet, web content mining has attracted increasing attention around the world from a growing number of researchers. From the perspective of applied research, Knowlesys keeps track of the latest theories and research focuses to develop innovative and powerful information processing tools through continuous learning and experimentation.
Leading web data mining technology
Our web data mining technology is built on our own theories and practices. Our theories are based on academic papers on network information acquisition worldwide and the theoretical exploration. Our practices derive from years of experience in the net data mining service and the analysis of more than a thousand websites of various types. In the initial stage of research, we were inspired by the following papers:
The Anatomy of a Large-Scale Hypertextual Web Search Engine
As a classic paper on modern search engines, it was published as a doctoral dissertation by Sergey Brin and Lawrence Page, the co-founders of Google, at Stanford in 1998. The paper proposed two important technologies: one is the implementation of centralized storage and indexing of Internet web pages distributed worldwide; the other is the use of interlinked information between web pages, the semantic information and structural information of text in web pages to improve the quality of search results.
Learning Information Extraction Rules For Semi-Structured and Free Text by Stephen
Soderland, a professor from Computer Science Dept. of Washington State University The paper has been quoted for over 50 times. Taking the information extraction system WHISK as an example, the paper describes a technology that implements automated information extraction in a pattern that uses a small sample size to train the system to automatically learn the extraction mode of target text. This technology is not only inspiring but also practical.
Extracting Patterns and Relations from the World Wide Web
It is another masterpiece of Sergey Brin. The paper introduces a method called DIPRE that uses the machine learning theory to automatically extract patterns and relations from massive texts. The paper describes the method that extracts book information from distributed texts on the Internet, i.e. author-title 2-tuple. It turns out that with a sample set of only 5 books, it automatically finds 15,000 books, of which some cannot be even found at Amazon, the largest online bookstore.
Leading software engineering
Knowlesys captures the real needs of prospective users in the client-oriented software development process and develops an accurate understanding of them. Before development, a system design model description is developed and functional and interface design blueprints of the software are drawn. Based on them, we are able to communicate with users and get their feedback in order to accurately control the project scope and specific objectives and improve customer satisfaction. Knowlesys software development process follows the Microsoft Solution Framework (MSF) 3.1 released by Microsoft to ensure the project proceeds smoothly and is implemented successfully.
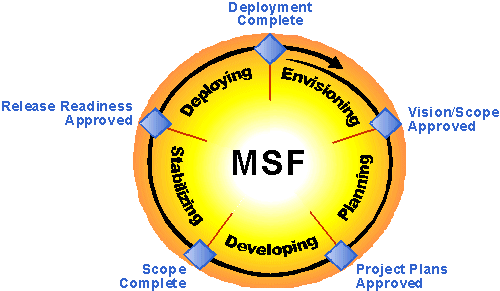
Fig. 1 Microsoft Solution Framework
Knowlesys designs applications by means of hierachicalization and componentization and implements them. The client interfaces have both the C/S Windows programs and the B/S Web programs.
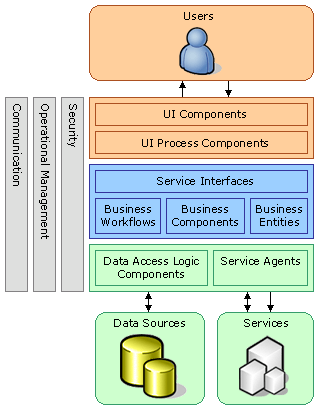
Fig. 2 Hierarchical and Componentization Models